Resampling with k-fold Cross Validation
k-fold “randomly divides the training data into k groups (or folds) of approximate size [with the model being] fit on k-1 folds and the remaining fold used to compute model performance.” I use k=5 or k=10 given that this is typical industry practice without really questioning “why?”
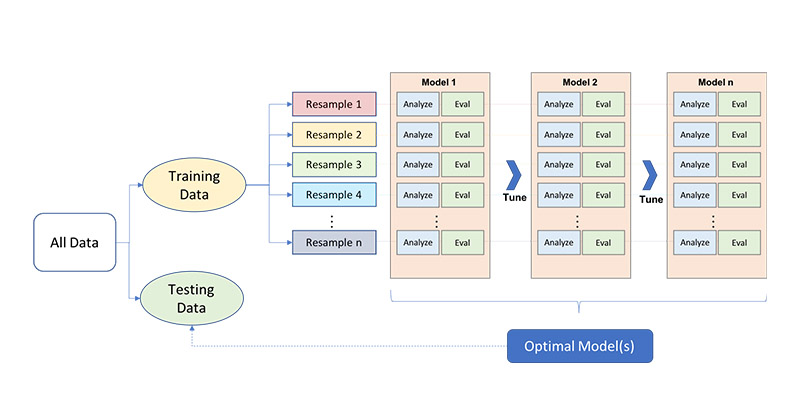
In reading through Hands-On Machine Learning with R by Brad Boehmke, Ph.D. and Brandon Greenwell, I was surprised to learn that studies have shown that k=10 performs similarly to leave-one-out cross validation where k=n.
Without realizing it, sometimes I get carried away optimizing code and drifting from statistics and the core “science” in data science… k-fold CV is a technique used by many and is agnostic to your statistical programming language of choice but if you’re an #R user, I can’t recommend this book enough (free in full online, link below)!
Source:
- Hands-On Machine Learning with R Chapter 2.4 Resampling Methods